I take immense pride in reading books as a source of knowledge, started with fiction during my student days and switched to anthropology, technology, science and leadership during the last twenty years. I usually list down the books I enjoyed reading during a year as blogpost but did not do it last year as I did not read many books in 2022. The same trend continued in 2023 albeit for additional reasons. I will list out these reasons intertwined with my experiments and conclude with my learnings through this process.
Time at work: During these last couple of years, I enjoyed spending a lot more time than usual at work. I addressed meaningful challenges by applying my past learnings from books and deep thinking aided by coaching that I covered in another blogpost. These opportunities for hands-on learning have been super satisfying, far greater than any book can offer.
Audible: Due to a couple of eye problems that I was trying to figure out root cause, I subscribed to Audible to check if listening to books can be an effective alternative. I felt good about this option after listening to “Atomic Habits” but did not work for two subsequent books, so gave it up for now. I usually read books before going to sleep and keep aside my book or kindle when I can longer focus on content. But with audible, I did not know when I stopped listening and lose track of the book easily.
OTT Platforms: The documentaries available over YouTube, CuriosityStream, Netflix and other OTT platforms provide latest and crisp content that are quite effective to acquire quick knowledge at a high level. I have explored these options for more than 5 years but have significantly increased reliance on them. In fact, some of the book references were from here.
Difficulty with finding high quality books of interest: Finally, I am quite picky when it comes to books and go through multiple reviews before starting to read one. Having read most of the classics and contemporary best books in my areas of interest over the last twenty years, finding new ones is difficult. I don’t mean to be disrespectful to the numerous awesome authors who spend their lifetime writing books. Just that I am a slow reader who takes almost a month for a 300-page book with limited time at my disposal. With other compelling options to acquire knowledge having emerged over the last decade, I need to pick the best horses for courses so that I don’t become a dinosaur.
The books I read over the years have helped me become who I am today and am sure they will continue to play a key role in shaping me in future too. There were times in the past when I felt a sense of accumulating learning debt when I don’t read books for a few months at a stretch. However, I did not feel that way during the last couple of years due to my experiments covered above. Having said that, I want to read at least five books in 2024 to check what I missed during the last couple of years and will start the new year by compiling my reading list!
I have learnt a lot from people, experiences, books and online resources during my 25-year professional career. For the first time, I had the good fortune of formal coaching interventions during 2023 and benefited from three different coaches. All of them helped me understand my strengths and improvement opportunities to come up with a credible development plan.
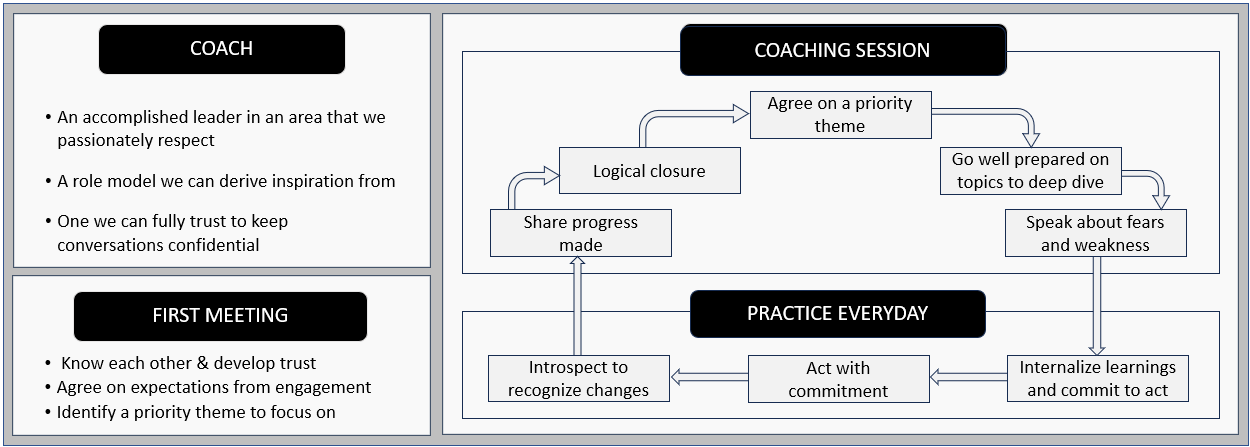
I am not a certified coach, so with this call out, let me start with my personal perspective on who can be a coach. It should be a leader who is accomplished in an area that we passionately respect, one we consider role model and derive inspiration from. A coach is not a teacher or manager who can instruct on what we should do. Rather, a coach helps in discovering ourself by asking questions that enables introspection and offers possible solutions when asked, leaving the decision choice to us. Most importantly, a coach should be one we can fully trust to keep conversations confidential.
All my three coaches had distinct approaches and each one of them helped me immensely in different ways. One common factor was rich experience that I have learnt from. It is important for us to understand our coach and figure out how to leverage the opportunity. The rest of the blogpost covers how I accomplished it.
Knowing each other: I mentioned trust as an important factor in a coaching relationship and we cannot trust strangers. So, it is important to start the engagement by knowing each other. In my case, I already trusted one of my internal coaches and an informal breakfast conversation with the other covered this part. While we are likely to know any internal coaches to some extent, I did some research on my external coach before the first conversation. This helped me strike a good chord during the first conversation and build trust.
Agree on expectations: Once the “knowing” part is complete, the first meeting should also cover setting ground rules and expectations. It is important to recognize that the coachee is the primary benefactor and should drive the engagement.
Identify a priority to focus on: Two of my coaches asked me questions and pretty much took control of the engagement, which made it easy for me. I still had to follow-up on discussion points and demonstrate that I am serious about learning from them for self-improvement. While there are many themes and topics that might be of interest for coaching engagement, I focused on one or two at a time, delved deep over multiple conversations before moving on to others. It is ideal to end the first meeting with the priority theme to start with.
Go well-prepared: This is possibly the most important part of the process to benefit from the engagement. The coachee should diligently follow-up on any previous discussions and start every meeting with those updates followed by listing down items wish to be covered.
Speak about our fears and weakness: My best learnings were when my coach acted as a mirror reflecting my weaknesses and suggested solutions from their experiences. When we stand in front of a mirror with make-up, we cannot diagnose imperfections accurately and the results from any follow-up actions will not be effective. The whole point of trust is to be able to confide with our vulnerabilities without concerns of being compromised.
Internalize learnings, act with commitment, and introspect to recognize changes: Coaching conversations and like leadership development programs. Many go into those programs expecting magical transformation and growth overnight, and get disappointed after a few months when they realize nothing much has changed. We should understand these interventions are a source of new ideas that we need to internalize and consciously practice over long periods before expecting results. Due to slow and incremental changes, we might not even notice them ourselves but will be good to introspect regularly to recognize progress. It is like looking at our own pictures from several years back that usually leave us admiring either our present or the past.
Share progress made: I consciously share with my coaches success stories resulting from coaching engagements that made me proud and further reinforced changed behaviors. I believe this will also be an encouragement to the coach as leaders love to hear about positive difference they made to others!
Logical closure: You can’t be stuck on the same theme or topic forever. If that happens, the coaching engagement is not really meeting the objective. I try to conclude a theme with an agreement on future course of action and move to the next one. The cycle starts again with the next priority theme.
Once again, these are just my perspectives on coaching based on my experiences so far and might differ from what coaching manual says. As I learn further, will update this post with any changes. In conclusion, want to thank my coaches and my leadership who gave me this opportunity and this blogpost is a tribute for their help to become a better version of myself!
I had the honor of delivering keynote address for a panel discussion on redesigning the future of business during the Annual HYSEA Summit & Awards 2023. The idea was to set the stage by emphasizing how digital technologies are disrupting businesses and challenges encountered by the IT industry post pandemic with 100% remote work impeding the ability to build deep expertise. You can watch my 8-min key note here.
I was invited to be the Guest of Honour at the Graduation Day for the Class of 2022 of HITAM (Hyderabad Institute of Technology and Management). This was my first time playing this role and should thank Ms Sheenam Ohrie, Broadridge India MD for providing this opportunity. A special thanks to Mr Vamsi Koka, Dean – Strategy & Operations and the leadership at HITAM for making it a memorable experience. It was a great honour to be at the stage with Padmashri Prof Sanjay Dhande, Former Director of IIT Kanpur and the Chairman of the Governing Body of HITAM who graced the occasion as the Chief Guest.
I have heard some legendary speeches from great leaders addressing students during their commencement or graduation ceremonies and wanted to make some sense during my five-minute message to the students. It was about six months since these students completed their engineering curriculum and all of them should have started their career as a professional or an entrepreneur or should be pursuing higher studies. So, I shared three essential qualities that have served me well throughout my professional career over the years. I strongly believe they will help anyone who want to succeed in their life:
Aspiration: A strong hope and ambition of achieving something has differentiated humans from other animals. It is the aspiration of humanity that led to agricultural, scientific, industrial and information technology revolutions over the last ten thousand years. As Sir Isaac Newton said “If I have seen further than others, it is by standing upon the shoulders of giants”. Each one of us have the opportunity to be such a giant for our posterity if we are aspirational with a meaningful purpose and vision.
Inspiration is the urge to do something and can trigger an aspiration or at times can also help achieve an ambition. As we grow up, we are inspired by several people and some of them also become role models. Personally for me, my parents have been an inspiration, a number of sports people and exceptional achievers in several fields have inspired me. We get inspired by nature as well, remember the legendary story of Robert Bruce being inspired by a spider and just imagine the sheer beauty of the world around us. We all are inspired by different things, but is it most important to follow that urge and strive to become an inspiration for others through our success.
Relentless perseverance: Once we are inspired and commit to be aspirational, the next step is relentless perseverance towards our goal. Many of us dream of luxury and expect it to make us happy. But try to remember the moments that you cherish the most in life and the ones that you are most proud of. Are they the time you spent in luxurious comfort or your achievements overcoming massive difficulties through hard work with sustained intensity and enduring pain towards a meaningful purpose? It is usually the latter.
I strongly encourage you to aspire, inspire and perspire towards your goals. We all have limited time in this world and every day, hour and minute is precious. Before you decide on how to spend this precious time, think how you will feel about your choice ten years from now. We are fortunate to be living at a time when knowledge is democratized and each one of us have numerous opportunities to make a difference. Please make it count to take yourself and your community forward.
I jotted this down as a blogpost so that I can see for myself ten years from now on how I feel about this!
One of the few books that keeps coming to my mind and reminds me of my north star every time I need help is “The Fifth Discipline – The Art & Practice of The Learning Organization” by Peter Senge. I have used the principles and learnings from this book countless number of times during the last ten years since I read this book. 2022 has been an extremely busy year for me at work and have neither been able to read many books nor post any blogs. So, thought I will celebrate tenth anniversary of reading this book by sharing the key learnings from this book here.
Peter Senge aptly uses the example of aviation technology taking more than thirty years to serve general public after Wright brothers invented flying to highlight that an idea moves from invention to innovation only when diverse “component technologies” comes together to integrate an ensemble of technologies that are critical to one another’s success. Similarly, there are five “component disciplines” are gradually converging to innovate learning organizations. They are – Personal Mastery, Mental Models, Building Shared Vision, Team Learning and Systems Thinking. While the first four are effective on their own to a certain extent, the fifth discipline of Systems Thinking integrates the other disciplines, fusing them into a coherent body of theory and practice.
This blog post is not about these disciplines or even Systems Thinking but lists out two key topics that provides an understanding and basis for the core disciplines for building a learning organization. These topics are the 7 Learning Disabilities that lead to individuals and organizations failing in the long term and the 11 Laws of the Fifth Discipline that enables an organization to sustain its ability to learn and grow.
Learning Disabilities: We have seen a number of well-established companies vanish over a short period of time. A study estimates that the average lifetime of the largest industrial enterprises is less than forty years, roughly half the lifetime of a human being! We have seen a number of industry leaders disappear during the last fifteen years, the ones relevant to our context will be Blackberry, Nokia, Kodak and Blockbuster to name a few. In all these companies, there was abundant evidence in advance that the firm was in trouble. The evidence goes unheeded, though the individual managers are aware of it. The organization as a whole cannot recognize impending threats, understand the implications of those threats or come up with alternatives. This is a reflection of these organizations failing to learn, which could be due to a number of reasons – they way they are designed and managed or the way people’s jobs are defined. Most importantly, the way we have all been taught to think and interact create fundamental learning disabilities. It is important that we learn to recognize when these disabilities occur and take corrective action.
I am my position: We are trained to be loyal to our jobs – so much so that we confuse them with our own identities. When people in organizations focus only on their position, they have little sense of responsibility for the results produced when all positions across the organization interact. Moreover, when results are disappointing, it can be very difficult to know why and the default assumption is that “someone else screwed up”.
The enemy is out there: Humans have the propensity to find someone or something outside ourselves to blame when things go wrong. In a Product Development organization, it is common for business analysts and testers to blame developers – “if only developers write quality code, we can satisfy customers”. Developers and business analysts blame testers – “if only QA tests important scenarios, we can prevent defects in production”. Testers and developers blame business analysts – “if only BAs provide proper requirements, we can deliver solutions that customers really need”. “The enemy is out there” syndrome is actually a by-product of “I am my position” , and the non-systemic ways of looking at the world that it fosters.
The illusion of taking charge: Many a times, managers proclaim the need for taking charge in facing difficult problems, be proactive in approach rather than react. But if we simply become more aggressive fighting “the enemy out there”, we are only reacting. True proactiveness comes from seeing how we contribute to our own problems.
The fixation on events: Conversations in many organizations are dominated by concern with short-term events like new budget cuts, who just got promoted or fired, missed milestone, etc. Our fixation of events is actually part of our evolutionary programming where our ancestors primarily needed only the ability to react to immediate threats to survive another day. However, if we focus on just events, the best we can ever do is predict an event before it happens so that we can react optimally. But we can never learn to create.
The parable of the boiled frog: If you place a frog in a pot of boiling water, it will immediately try to scramble out. But if it is water at room temperature that is heated slowly, it will become groggier until it is unable to climb out of the pot. Similarly, we are also tuned to sensing sudden changes in our environment, but not to slow, gradual changes. We slip into what is famously referred as comfort zone and becomes very difficult to get out of it.
The delusion of learning from experience: We learn from our experience but never directly experience the consequences of many of our important decisions. The most critical decisions made in organizations have systemwide consequences that stretch over years or decades.
The myth of the management team: Every organization has a management team that is a collection of savvy, experienced managers who represent the organization’s different functions and areas of expertise. All too often, the managers tend to spend time fighting for turf, avoiding anything that will make them look bad personally and pretending that everyone is behind the team’s collective strategy.
This book covers these learning disabilities to highlight the need for the five disciplines of the learning organization. After I read this book ten years back, I consciously take a step back once in a while to introspect and look for any of these disabilities in myself and try to overcome if I found any.
The Laws of the Fifth Discipline: Systems Thinking that enables understanding complexity is the cornerstone of the learning organization. The eleven laws of this discipline helps us look at problems and opportunities holistically and avoid pitfalls of siloed thinking.
Today’s problems come from yesterday’s “solutions”: Often we are puzzled by the causes of our problems, when we merely need to look at our own solutions to other problems in the past. For example – an organization that prioritizes reducing time to market thereby rushing a product to the market ends up dealing with quality issues and frustrated customers. Solutions that merely shift problems from one part of a system to another often go undetected because those who solved the first problem are different from those who inherit the new problem.
The harder you push, the harder the system pushes back: Well-intentioned interventions to solve a problem call forth responses from the system that offset the benefits of the intervention, this phenomenon is called “compensating feedback”. For example – a person quits smoking to become more healthy but ends up gaining weight and suffers such a loss in self-image that he takes up smoking again to relieve the stress. When our initial efforts fail to produce lasting improvements, we push harder without understanding compensating feedback.
Behavior grows better before it grows worse: Low-leverage interventions to solve problems actually work in the short-term as compensating feedback usually involves a delay. We declare victory too early and a new problem eventually shows up elsewhere in the system that someone else needs to solve now.
The easy way out usually leads back in: We find comfort applying familiar solutions to problems, sticking to what we know best as it is easy for us. Pushing harder on familiar solutions while fundamental problems persist or worsen is a reliable indicator of non-systemic thinking reflecting “what we need here is a bigger hammer” syndrome
The cure can be worse than the disease: Sometimes familiar solutions are not only effective but also addictive and dangerous. Alcoholism may start as simple social drinking to relieve stress but causes addiction and bigger problem in the long-term.
Faster is slower: Organizations often go for quick fixes for problems that deliver results fast but don’t last long, despite being aware that solutions that stick take longer to show results.
Cause and effect are not closely related in time and space: We tend to address symptoms rather than root cause as symptoms are readily visible while the real causes might have occurred at a different time. The first step in correcting this mismatch is to let go of the notion that cause and effect are closely related in time and space.
Small changes can produce big results – but the areas of highest leverage are often the least obvious: We are usually tempted to go for familiar solutions to problems as they are the most obvious and easy to understand and implement. Understanding the system as a whole and deep analysis to identify the real underlying issue will help identify those small changes that have the potential to deliver the most.
You can have your cake and eat it too – but not at once: Sometimes the knottiest dilemmas, when seem from systems point of view, are not dilemmas at all. They may just be false dichotomies. For example, we might not have to make a choice between quality and cost. They may both go up in the short-term but reduced rework in the long-term can bring in the required cost savings.
Dividing an elephant in half does not produce two small elephants: Organizations are living systems that have integrity. Their character depends on the whole. Understanding the most challenging managerial issues require seeing the whole system that generates these issues. Dividing the system into silos can break this integrity.
There is no blame: We tend to blame “others” for our problems. Systems thinking shows that there is no separate “other”, that you and the “other” are part of a single system.
Understanding the learning disabilities and the laws of systems thinking has helped me getting to the root of many problems over the years. It also prevented me from falling into the trap of familiar solutions that provide short-term relief but lead to bigger problems in the long-term.
I began 2022 with Adam Grant‘s latest book “Think Again: The Power of Knowing What You Don’t Know“. This book is an invitation to let go of knowledge and opinions that are no longer serving us well, and to anchor our sense of self in flexibility rather than consistency. This also means abandoning some of our most treasured tools and some of the most cherished parts of our identity.
The key is “rethinking” – adopting mental flexibility to let go of our long held assumptions and have the courage to challenge our self-beliefs that might have led to success in the past but no longer relevant for the future. As an example, the COVID-19 pandemic has forced organizations to rethink the value of co-located teams working in close physical proximity all the time to deliver projects. Instead, all organizations are now exploring the flexibility offered by remote work for people to balance their professional and personal goals better. Contrary to long held belief, many remote teams have been more productive working from home as they repurposed unproductive time spent on activities like the office commute. It does not mean that remote work will be the better option forever, we are certain to encounter new challenges and we need to rethink again to address them.
This book makes a case for rethinking at three levels – Individual, Interpersonal and Collective.
Individual Rethinking – Updating our own views:
A Preacher, a Prosecutor, a Politician and a Scientist walk into your mind: Our assumptions and beliefs often drive us towards two biases – Confirmation bias (seeing what we expect to see) and Desirability bias (seeing what we want to see). These biases contort our intelligence into a weapon against the truth. We find reasons to preach our beliefs more deeply, prosecute our case more passionately and ride the tidal wave of our political party. The tragedy is that we are usually unaware of the resulting flaws in our thinking. To avoid this conundrum, we should think like a scientist, and NOT like a preacher or a prosecutor or a politician. Thinking like a scientist requires searching for reasons why we might be wrong and revising our views based on what we learn.
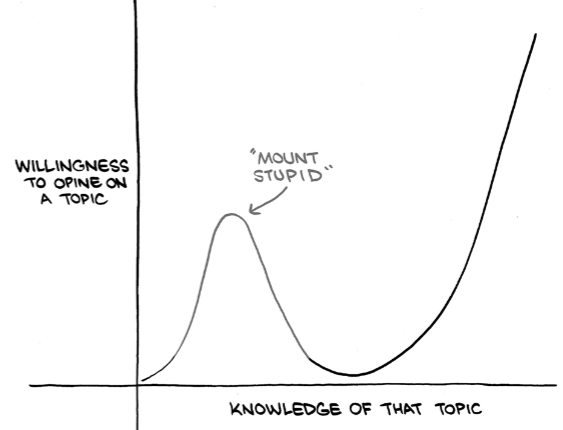
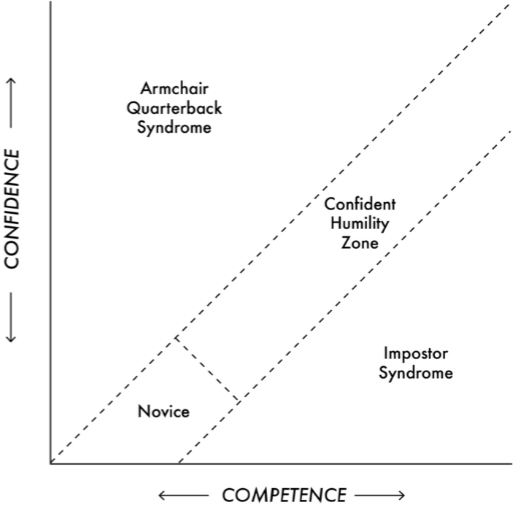
The Armchair Quarterback and the Imposter – Finding the sweetspot of confidence: Knowledge on a topic leads to both competence and confidence, the balance between both of them will determine our personality. We need to be careful when we progress from being a novice to an amateur in a skill as this is the stage when we tend to become overconfident reaching the summit of what is called “Mount Stupid“. As we progress further towards becoming a professional, we realize there is a lot more to learn and usually become more humble. We should strive to reach a state of “Confident Humility” – having faith in our capability while appreciating that we may not have the right solution or even be addressing the right problem. This gives us enough doubt to reexamine our old knowledge and enough confidence to pursue new insights.
The Joy of being Wrong: Most of us are accustomed to defining ourselves in terms of our beliefs, ideas and ideologies. This can become a problem when it prevents us from changing our minds as the world changes and knowledge evolves. Our opinions become so sacred that we grow hostile to the mere thought of being wrong, and the totalitarian ego leaps in to silence counterarguments, squash contrary evidence and close the door on learning. Instead, it is better we define ourselves by our values. Values are our core principles in life – like respect, fairness, empathy, trust, courage, etc. Basing our identity on these kinds of principles enables us to remain open-minded and enjoy instances when were go wrong as opportunities to learn.
The Good Fight Club – The psychology of constructive conflict: High performing groups thrive on task conflict to bring the collective best by challenging different views with mutual respect (so that it does not slip into relationship conflict).
Interpersonal Rethinking – Opening other people’s minds:
Dance with Foes – How to win debates and influence people: When we want to convince others to rethink their opinions, we frequently take an adversarial approach that effectively shuts them down or rile them up instead of opening their minds. They play defense by putting up a shield, play offense by preaching their perspectives and prosecuting ours, or play politics by telling us what we want to hear without changing what they actually think. The better approach will be a more collaborative one, where we show more humility and curiosity, and invite other to think more like scientists. A good debate is not a war, it is more like a dance that has not been choreographed, negotiated with a partner who has a different set of steps in mind. To accomplish this, expert negotiators use a few techniques: acknowledging common ground, presenting fewer reasons to support their case and expressing curiosity with intriguing questions.
Bad Blood on the Diamond – Diminishing prejudice by destabilizing stereotypes: In every human society, people are motivated to seek belonging and status. Identifying with a group checks both boxes at the same time: we become part of a tribe and we take pride when our tribe wins. This leads to rivalries between tribes (teams) that are typically geographically close, compete regularly and are evenly matched. Some examples in sports is rivalry between India and Pakistan on cricket or between the Yankees and Red Sox in baseball. To reinforce the rivalry, stereotypes are formed and for both mental and social reasons it is hard to undo them. Some of the ways to overcome stereotypes are: come up with shared identify using commonalities (overview effect), humanizing the team and focusing on an individual to explain irrationality of the stereotype.
Vaccine Whisperers and Mild Mannered Interrogators – How the right kind of listening motivates people to change: People with unhealthy additions or unscientific beliefs are usually aware of their fallacies. If we try to persuade them to make a change, we evoke resistance and they are less likely to change. We can rarely motivate someone else to change, instead we are better off helping them find their own motivation to change. “Motivational Interviewing” is a practice that can help with this. Motivational interviewing starts with an attitude of humility and curiosity. Our role is to hold up a mirror so they can see themselves more clearly, empower them to examine their beliefs and behaviors that can activate a rethinking cycle. Three key techniques for motivational interviewing are: asking open-ended questions, engaging in reflective listening and affirming the person’s desire and ability to change.
Collective Rethinking – Creating communities of lifelong learners:
Charged Conversations – Depolarizing our divided discussions: As humans, we have the tendency to seek clarity and closure by simplifying complex continuum into two categories. This is called binary bias. While democratization of information through internet was expected to expose us to different views and help us make informed rational decisions, binary bias has instead led to a more polarized world. To overcome binary bias, a good starting point is to become aware of the range of perspectives across a given spectrum and articulate the complexity instead of simplifying it. Some techniques to convey complexity are: including caveats, highlighting contingencies and expressing mixed emotions.
Rewriting the Textbook – Teaching students to question knowledge: With so much emphasis placed on imparting knowledge and building confidence, many teachers don’t do enough to encourage students to questions themselves and one another. It is important to instill intellectual humility, disseminate doubt and cultivate curiosity to develop students of today into confidently humble experts in their respective domains tomorrow.
That’s Not the Way We Have Always Done it – Building cultures of learning at work: Rethinking is more likely to happen in a learning culture, where people strive to know what they don’t know, doubt their existing practices and stay curious. To achieve this “Psychological Safety” – fostering a climate of respect, trust and openness in which people can raise concerns and suggestions without fear of reprise – is essential. In performance cultures, the emphasis on results often undermines psychological safety. When we see people get punished for failures and mistakes, we become worried about proving our competence and protecting our careers. While many organizations strive to build high performance cultures with the right intention, care should be taken to ensure psychological safety in parallel to promote learning culture. Psychological safety should be combined with process accountability to create a learning zone where people feel free to experiment and to poke holes in one another’s experiments in service of making them better.
Adam Grant concludes by making a case for regularly reconsidering our best-laid career and life plans to escape tunnel vision that hampers our growth. He leaves us with specific actions for impact, which are his top thirty practical takeaways for working on our rethinking skills. I will conclude this blogpost with these takeaways.
Most of the books I read last year were on leadership and technology, with a notable exception in “Born to run” that vividly covered a Mexican Indian running tribe. I will start with a super trio of books around leadership communication and list the most interesting books read last year.
This is the first of the trio around leadership communication. The definition – A story is a fact wrapped in context and delivered with emotion breaks a general misconception that stories are usually fiction created by professional writers for novels or movies. It goes on to explain why stories are the most effective way to communicate a message at work and how they can be used for building credibility, overcoming objections, getting strategies to work or articulating successes. You can find my blogpost on “Stories at work” here.
We are all influenced at times by the irresistible pull of irrational behavior. This book explains the science behind this behavior and can help avoid potential pitfalls due to certain psychological undercurrents: loss-aversion, swamp-of-commitment, value-attribution, diagnosis-bias, self-perpetuation, fairness-of-process and group-conformity. You can find my blogpost on “Sway” here.
This is the last of the trio on leadership communication. Once we understand how to use stories at work and are aware of the psychological undercurrents that lead to irrational behavior from the first two books, this one explains the science behind “The Stickiness Factor” that leads to long lasting messages. It identifies the traits that make ideas sticky and provides a checklist for creating a SUCCESsful idea: a Simple Unexpected Concrete Credentialed Emotional Story. You can find my blogpost on “Made to Stick” here.
SRE is among the most popular technology topics during the last few years, with the IT industry viewing it as a better way to run production systems by applying a software engineering mindset to accomplish the work that would typically be performed manually by sysadmins. This book by hands-on masters of the domain provides compelling insights and motivation to transform the way technology org manages system operations. I documented learnings from the book “as-is” in my four-part blogpost series. Once we embarked on actual org transformation, we realized that realities in every org (particularly one that has legacy technology with monoliths and not truly services like Google) means one-size-fits-all approach will not work. However, this book provides some solid guiding principles that can help any org shift towards engineering oriented approach to running production systems.
Born to Run – Christopher McDougall
Being a compulsive runner myself and having found the pain of running marathons to be fun, this book was sheer joy! It is all about the mysterious Mexican Indian tribe of Tarahumara and readers who enjoy this book will be inspired to become long distance runners. I hope to visit Copper Canyons one day and be able to run along the treacherous trails vividly described in this book.
Deep Work – Cal Newport
We are living in a digital world surrounded by numerous electronic devices constantly distracting us with unending notifications. This has resulted in a lot of us finding it difficult to “focus without distraction on a cognitively demanding task“, which this book refers as “deep work” and which is an important skill to get any complex work done. Cal Newport has shared some surprising practices used by experts to switch to deep work along with emphasizing the need to embrace boredom and quitting social media to remove distractions.
This book is referred by Deep Work, as an execution technique to achieve what needs to be done. The authors explains how the urgent day-to-day operational tasks that are referred as whirlwind impedes leaders at large organizations from executing important strategic goals. They also provide a four step framework to overcome this difficulty and excel at execution – focusing on the wildly important, acting on the lead measures, keeping a compelling scorecard and creating a cadence of accountability. You can find my blogpost on 4DX here.
We have come across several urban legends that resonate with people though they are unbelievable and false, while some of the most potent transformational ideas are not even considered. The traditional belief is that successful communication requires getting the right people and setting the right context. But there is another factor that is key for an idea to become viral – “The Stickiness Factor” as explained by Malcom Gladwell in The Tipping Point. This blog is about a different book Made to Stick by Chip and Dan Heath, which identifies the traits that make ideas sticky and provides a checklist for creating a SUCCESsful idea: a Simple Unexpected Concrete Credentialed Emotional Story.
Simple: Great simple ideas have an elegance and a utility that make them function a lot like proverbs: short sentences (Compact) drawn from long experience (Core). Simple = Core + Compact
Finding the core requires stripping down an idea to its most critical essence. To get to the core, we have start with weeding out the superfluous elements and eventually get down to the tougher part of eliminating ideas that may be really important but just aren’t the most important idea.
Creating a compact message is the next step once the core is identified. Compactness is all about elegance, prioritization and being crisp. It should not result in dumbing down or shooting for the lowest common denominator to make things easy. Techniques like “inverted pyramid” used by journalists to present information in descending order of importance and “forced prioritization” limiting to just one thing, are helpful.
A few examples of simple ideas that are compact while retaining the core idea:
SouthWest Airlines tagline: THE low-fare airline.
Bill Clinton’s 1992 campaign lead: It’s the economy, stupid.
Unexpected: The first problem of communication is getting people’s attention. The most basic way to get someone’s attention is by breaking a pattern as humans adapt incredibly quickly to consistent patterns. For example, we quickly get used to certain sounds like that of our air-conditioner or ceiling fan and certain smells like a room freshener or candle, that we become consciously aware of these things only when something changes. To get people’s attention and keep it, naturally sticky ideas provoke two essential emotions: Surprise and Interest.
Surprise gets our attention. Some naturally sticky ideas propose surprising “facts”. Like the statement “You use only 10% of your brain”.
Interest keeps our attention. Interesting ideas like conspiracy theories or gossips makes us keep tab on developments thereby maintaining our interest over time.
The Gap Theory of curiosity: Curiosity happens when we feel a gap in our knowledge and these gaps cause pain till they are filled. To leverage the gap theory, we sometimes have to set the context and give people enough backstory that they start to care about the gaps in their knowledge. Mystery novelists and crossword puzzle writers excel in this technique by setting some context and giving us clues that generate sufficient interest when curiosity takes over and propels us to finish!
Concrete: As we master a language, we use complex words and abstraction to make our point. When we deliver our beautiful abstract message, listeners admire our mastery over language and extensive vocabulary. However, abstraction makes it difficult to understand an idea and remember it. It also makes it harder to coordinate our activities with others, who may interpret the abstraction in different ways. Concreteness helps us avoid these problems:
Concrete is memorable: When we are asked to remember how a beach feels, our sense memories are immediately evoked bringing back memories of the sight of sand and waves, smell of the ocean, sea breeze blowing across our face, etc. For a person who has not seen a beach at all, it is only the textbook definition of beach that comes to mind at best and cannot relate to it as well.
Concrete allows coordination: Abstract statements can mean different things for different people. For example, a goal to manufacture “the best car” will mean top speed for a race driver while it will mean comfort and space for a person looking to drive his family of four for a picnic. So, making it concrete with tangible aspects like “the car that can comfortably accommodate a family of four along with ample space to carry picnic bags” will help effectively coordinate within a team and reduce scope for different interpretations.
Credible: People’s beliefs are based on years of trust built in family, personal experience, faith and authorities. However, we can’t always rely on these factors to vouch for our message. Most of the time our messages have to vouch for themselves and must have “internal credibility”, which can be obtained from three sources:
Details: A person’s knowledge of details is often a good proxy for expertise. Vivid details shared along with the message will increase the credibility of the idea.
Statistics are a good source of internal credibility when they are used to illustrate relationships. Using “human-scale principle” will make statistics more effective and allows people to bring their intuition to bear in assessing whether the content of the message is credible.
The Sinatra Test: In Frank Sinatra’s classic “New York, New York”, he sings about starting a new life at New York City and the chorus declares, “If I can make it there, I will make it anywhere”. An example passes the Sinatra test when just that instance is enough to establish credibility in a given domain. For example, if you have driven on Indian roads, you can drive anywhere.
Emotional: Accidental mutation of human brain thousands of years back led to cognitive revolution resulting in agricultural, scientific and industrial revolutions through analytical thinking that set us apart from other animals. However, most of our actions are still driven by primitive emotions or feelings invoked by an event. As we prepare to communicate our idea, it will help to remember that using statistics or science to make our point shifts people into a more analytical frame of mind. When people think analytically, they are less likely to think emotionally that makes them care for something. There are three strategies for making people care:
Using associations (or avoiding them as the case may be): Piggybacking strategy associating ideas with emotions that already exist.
Appealing to self-interest: Highlighting what is in it for oneself is a powerful way of engaging people with an idea.
Appealing to identity: In some cases, going beyond self-interest and appealing to an identity that people care about will be impactful.
Stories: There are numerous books highlighting why stories are the most effective means of communicating messages at work and I have a blogpost on one of them. “Made to stick” highlights that stories cause mental simulation that evokes the same modules of the brain that are evoked in real physical activity. So, while mental simulation is not as good as doing something, it is the next best thing. There are three basic plots that can be used to make our ideas stick:
The Challenge Plot: Obstacles seem daunting to the protagonist and the triumph of will power over adversity inspires us to act.
The Connection Plot: These are about our relationships with other people and will be a good way to build relationships.
The Creativity Plot: Involves someone making a mental breakthrough, solving a long standing puzzle or attacking a problem in an innovative way.
To summarize, for an idea to stick and be useful for a long time, it has to make the audience:
Can you remember instances when you decided to pursue a course of action that went against your professional training?
Have you wondered why leaders at times make silly mistakes by ignoring the obvious?
The question when we look back at such incidents invariably is: How can a professional with such established reputation and years of experience do this?
Leaders have to make decisions all the time based on available data and with no guarantee of success. Though they typically have the best interests of their organization in mind, sometimes things do go wrong and posterity can attribute at least some of the failures to past “irrational” decisions. It is usually easy for people to provide elaborate commentary on poor results with hindsight bias. Does this mean all leaders are doomed to be criticized in the future? Brafman Ori’s book “Sway: The Irresistible Pull of Irrational Behaviour” can help leaders deal with this occupational hazard during decision making by being aware of potential pitfalls due to certain psychological undercurrents: loss-aversion, swamp-of-commitment, value-attribution, diagnosis-bias, self-perpetuation, fairness-of-process and group-conformity.
The first time I came across the concept of irrational behavior was in the Dan Ariely’s book “Predictably Irrational” several years back. It was before I started blogging and when I was still reading non-fiction for fun rather than leadership insights. Brafman Ori has taken it to the next level by explaining the reasons behind these irrational behaviors and also shares some practices that can help us avoid falling into the trap.
History is filled with numerous instances of top-notch, award-winning professionals making a choice that contradicted their years of training resulting in disastrous outcomes as they swayed from the logical path. This book explores some of the psychological forces that derail rational thinking: how they creep upon us, when are we most vulnerable to them and why don’t we realize that we are getting swayed. By better understanding the seductive pull of these forces, we will be less likely to fall victim to them in the future.
Loss Aversion – tendency to go to great lengths to avoid potential losses: Human mind naturally experiences the pain associated with a loss much more vividly than it does the joy of experiencing a gain. This results in our overreacting to perceived losses for no apparent logical reason. The more meaningful a potential loss is, the more loss averse we become and get swept into an irrational decision. Some examples of this behavior are people subscribing to expensive “unlimited” phone or internet plans to avoid perceived loss associated with pay-as-you-go, investors in financial markets concentrating on avoiding losses rather than focusing on maximizing their gains, etc.
Swamp of Commitment – hanging on to a strategy even if the chances of success are small and the cost of delaying failure is high: History is filled with stories of civilizations and companies vanishing by sticking to a committed path even after realizing the need to change. It is also what leads a gambler or investor to chasing losses. Loss aversion and commitment have powerful effect on their own. But when they both combine, it becomes that much harder to break free and do something different.
Value Attribution – inclination to imbue a person or thing with certain qualities based on initial perceived value: From our childhood, we form perceptions about value. For example – premium branded products are preferred over regular ones even if packaging is all that is different, a lawyer is trusted more when he shows up wearing a fancy suit. We have mental models of how a top investment banker or computer geek or a seasoned politician will look like. Anyone who does not fit the stereotype finds it difficult to gain acceptance.
Diagnosis Bias – blindness to all evidence that contradicts our initial assessment of a person or situation: The proverb “The first impression is the best impression” is based on this psychological undercurrent. After all, the first impression might have occurred under exceptionally fortunate or unfortunate circumstances.
Self perpetuation – taking on characteristics assigned by diagnosis thereby reinforcing it: This is also called self-fulfilling prophecy or chameleon effect. When we brand or label people, they take on the characteristics of the diagnosis. It is also called Pygmalion effect when a positive trait is assumed and Golem effect in case of negative traits.
Fairness – its the process and not the outcome that causes irrational behavior: We expect procedural justice from people we deal with, which is perceived fairness of the process rather than just a fair outcome. For example, we consider a car salesman to be fair when he explains the reasons why the original price is worth every penny rather than another who gives an easy 10% discount without spending any effort to explain why this is the best possible deal. In the second case, we leave with the question of why only 10%, did the salesman really give me the best deal or did I overpay? To avoid this fairness dilemma, managers are asked to put greater effort, energy, investment and patience into nurturing relationships.
Group conformity – propensity to go along with the group and save the embarrassment of being odd person out: Regardless of how independent minded and steadfast people are, it is common for people to align with a group instead of voicing an unpopular viewpoint due to fear that others will doubt their intelligence, taste or competence. For a decision to be made by comprehensively considering all possibilities, it is important for the discussion to include initiators, blockers, supporters and observers. It might be frustrating to encounter blockers for what might appear to be an obvious course of action, but their opinions are absolutely essential to keeping groups balanced and hold back irrational behavior.
If this book were a movie, the first 90% is an intriguing build-up and the Epilogue is a fitting fast-paced climax where Brafman Ori gives us some invaluable suggestions on ways to avoid these pitfalls, some of them below:
Our natural tendency to avoid the pain of loss is most likely to distort our thinking when we place too much importance on short-term goals. When we adopt the long view, immediate potential losses don’t seem as menacing.
When we find ourselves unsure about whether or not to continue a particular approach, it is useful to ask – “If I were just arriving on the scene and were given the choice to either jump into this project as it stands now or pass on it, would I choose to jump in?” If the answer is no, then chances are we have been swayed by the hidden force of commitment.
The best strategy for dealing with the distorted thinking that can result from value attribution is to be mindful and observe things for what they are, not just for what they appear to be. You have to be prepared to accept that your initial impressions might be wrong.
“Propositional thinking” is all about keeping evaluations tentative instead of certain, learning to be comfortable with complex, sometimes contradictory information and taking your time and considering things from different angles before coming to a conclusion. Net-net, a self-imposed waiting period before making a diagnostic judgment can help avoid diagnostic bias.
One way to counter fairness sway is to try to weigh things objectively and not succumb to emotional maneuvers or moral judgments.
When we make decisions or take actions that will affect others, keeping them involved will help ensure that they feel the process is fair.
Just as communicating our process is important, so is giving voice to the dissenter. In group situations, the presence of a blocker can actually make the decision making process more rational and less likely to go off the track.
The ability to think has set humans apart from other animals and become all-conquering species. At the same time, our natural decision making machinery has limitations that leads us to being swayed at times by factors that have nothing to do with logic or reason. This book will help us recognize and understand the hidden world of sways, and learn to weaken their influence on our thinking process.