After reading a few heavy technology books since the beginning of 2021, I was looking for a relatively light read and that’s when my senior leader recommended “Stories at Work” by Indranil Chakraborthy. With a recommendation from such an accomplished orator and fantastic storyteller, I bought the book immediately to check on the techniques to benefit from. Being an engineer who takes pride in analytical approach to solve problems, I considered myself to be good at articulating facts and data points. And by false dichotomy, assumed that I cannot be a good storyteller. Indranil broke this myth with the following definition of stories in business and set the tone for some awesome insights!
A story is a fact wrapped in context and delivered with emotion
I usually start any new learning with understanding “Why” it is required. In this case I remembered Yuval Noah Harari’s Sapiens referring to human’s ability to tell stories as a key result of Cognitive Revolution that led to advancement of our societies. In addition, Indranil Chakraborthy provides six compelling reasons why stories are profoundly relevant:
- Evolutionary predisposition: Biologists confirm that human brain is predisposed to think in story terms and explain things in story structures. Our brain converts raw experience into story form and then considers, ponders, remembers and acts on a self-created story, not the actual input experience. So, the next time someone nods vigorously indicating understanding of your speech but says something completely different when asked to paraphrase, blame the human brain at work!
- Childhood story exposure: We have been telling children stories to teach them values, behavior and build their knowledge. This exposure to stories through the key years of development results in adults who are irrevocably hardwired to think in story terms.
- Chemical post-it notes: Daniel Goleman’s “Emotional Intelligence” covers this topic in detail – in essence, emotionally intense events are permanently registered in our emotional brain (amygdala) by neuro-chemicals for super-fast retrieval whenever similar events take place in future.
- Neural coupling: When a story is told and it has meaning, brain patterns of the speaker and the listener synch. This can be used to ensure listeners fully comprehend what one wants to convey.
- Monkey see, monkey feel: When someone describes pain they went through, we feel the same way. This is due to mirror neurons that are fired up in the minds of both the listener and the storyteller.
- Data brain, story brain: Stories impact more areas of our brain than data does and hence stories involve us much more. This increases the likelihood of us taking action when we hear stories and not just data.
To summarize why stories are a powerful way to communicate our message – In this world of increasing noise and clutter, an ability to find an expressway to the listeners’ minds can be the most powerful skill in a leader’s repertoire. Stories can be this expressway if laid out appropriately!
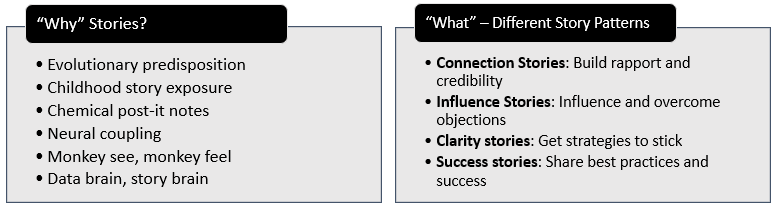
Now that we understand “Why” stories are important in business, the book explores “What” are the four situations where we can start our storytelling journey:
- Using stories to build rapport and credibility: When we meet a person or a group for the time, we start with an introduction that is usually filled with our credentials that we expect to build trust. While credentials are an indirect pointer to our character, we can be more effective in building trust by sharing anecdotes from our life. Indranil calls them “connection stories” that can help our listeners appreciate our values and result in forming a bond through shared values and beliefs. He also provides a step by step process to create and fine-tune connection stories:
- Before meeting a new group of people, write down five words or phrases abut your character, values or beliefs that you would like your listener to infer about you.
- Recollect and jot down an incident from your life where you have displayed many of these character traits.
- Narrate the incident to someone you trust and write down what they inferred about you from it.
- Based on the feedback, chisel down the story to just about a minute or less.
- Tell the story to two other people that will automatically help you refine it further.
- Retell the story to yourself, starting with the character trait you want your audience to take away.
- Finally, record your story, transcribe it and fine-tune further by brutally eliminating the words that are unnecessary.
- Using stories to influence and overcome objections: When people have a strong belief on an illogical idea, it is usually based on some personal experience or story. Using data or logic to debate against such belief will be futile. The only way to convince people to change under such scenario is to replace it with a more powerful story, which is called “influence story“. An influence story has to be introduced carefully, using the following steps:
- Acknowledge the anti-story: Empathize with the listener’s story and express understanding of reasons behind prevailing belief.
- Share the story of the opposite point of view: This is the step to replace with a more powerful story, will be ideal if it can be corroborated.
- Make the case: Without offending the listener’s views, explain the need for a change.
- Make the point: Finally call for action, maybe to experiment with the change first and see the results for oneself.
- Getting strategies to stick: Organizations come up with well-thought vision and value statements but many a times they don’t stick across the organization due to three key reasons – abstraction of language, absence of context or the curse of knowledge. To address these challenges, “clarity stories” using simple English with the following structure are used:
- In the past: Articulate how we succeeded in the past using strategy relevant at that time.
- Then something happened: Highlight the changes caused by both external and internal factors that have rendered the past strategy irrelevant.
- So now: Introduce the new strategy that needs to be adopted to succeed in current reality.
- In the future: Explain your vision on how this new strategy will create new opportunities and success in future.
- Using stories to share best practices, knowledge or success: Just like we tend to focus on credentials while introducing ourselves, the focus while articulating success or best practices tends to be data points or statistics. Given humans are predisposed to assimilate stories better, the suggestion here is to turn them into “success stories”. Narrate the success as stories placing human characters appropriately for effective reach and impact.
After covering “Why” and “What”, the book goes on to cover “How” to put them together for different business scenarios. I would recommend reading the book for this section (and the previous ones as well for comprehensive understanding).
To summarize, the combination of four story patterns – connection stories, influence stories, clarity stories and success stories – will make external and internal communication more effective and transform an organization. Happy story-telling!